

原文地址:http://songshuhui.net/archives/10462.html
许可协议:知识共享署名-非商业性使用-禁止演绎

这是个真实的故事。
从前在海岸边有一群扇贝在悠哉游哉地生活繁衍着。它们自然是衣食不愁,连房子也有了着落。它们担忧的只有一件事:每隔一段时间,总有一个人来挖走它们之中的一部分。当然啦,挖回去干什么这大家都知道。但扇贝们不知道的是,这人的家族图腾是Firefox的图标,所以他总是选择那些贝壳花纹长得比较不像Firefox图标的扇贝。
这种状况持续了好几十万代。大家应该也猜到扇贝们身上发生什么事情了:它们的贝壳上都印着很像Firefox图标的图案。
可能有些读者会说:你这不是糊弄我们么,Firefox才有多少年历史,你就搞了个几十万代的扇贝?
确有其事,但是这些扇贝不是真实的,它们在我电脑的内存里边生活。它们是一个遗传算法程序的一部分,这个程序的目的就是用100个半透明三角形把Firefox的图标尽可能像地画出来。
什么是遗传算法呢?
简单地说,遗传算法是一种解决问题的方法。它模拟大自然中种群在选择压力下的演化,从而得到问题的一个近似解。
在二十世纪五十年代,生物学家已经知道基因在自然演化过程中的作用了,而他们也希望能在新出现的计算机上模拟这个过程,用以尝试定量研究基因与进化之间的关系。这就是遗传算法的滥觞。后来,有人将其用于解决优化问题,于是就产生了遗传算法。
那么,具体来说,在计算机里边是怎么模拟进化过程的呢?
我们还是以开头提到的程序为例。
首先,我们知道,生物个体长什么样子很大程度上是由染色体上的基因决定的。同样,如果我们把100个半透明三角形组成的东西看成一个生物个体的话(为了说话方便,称为扇贝吧),我们也可以说它的样子是由这些三角形的具体位置和颜色决定的。所以,我们可以把一个一个的半透明三角形看作是这些扇贝的“ 基因”。而组成扇贝的这100个基因就组成了每个扇贝个体的“染色体”(chromosome)。
从下面的图可以大约看出来这些基因是怎么决定扇贝的样子的(为了观看方便,我们只画出其中五个三角形):

然后,扇贝们除了生活,当然还要繁衍后代。生物界中的繁衍无非就是父母的基因组合产生新的个体,而在这个程序里边我们当然也这么办:选择两个原有的扇贝,然后从这两个扇贝的染色体中随机选取一共100个基因组成新个体的染色体。如图所示:(仍然是将扇贝看成是五个三角形组成的)

为了产生新的基因,使基因的种类更多样化,在组合的时候,新的扇贝的基因有一定的概率发生变异。也就是说,其中的一个透明三角形的位置或者颜色会随机改变,如图(仍然是五个三角形……我偷工减料……):

其次,为了使扇贝的样子向Firefox图标靠近,我们要给它们加上一点选择压力,就是文章开头故事中提到的那个人的行动:在每一代把最不像 Firefox的扇贝淘汰出去,同时也给新的个体留下生存的空间。怎么评价这个扇贝像不像Firefox呢?最直接的方法就是一个一个像素比较,颜色相差得越多就越不像。这个评价的函数叫做“适应函数”,它负责评价一个个体到底有多适应我们的要求。
在淘汰的过程中,为了便于编程,我们通常会在淘汰旧个体和产生新个体的数目上进行适当的调整,使种群的大小保持不变。淘汰的作用就是使适应我们要求的个体存在的时间更长,从而达到选择的目的。
最后,在自然界中,种群的演化是一个无休止的过程,但程序总要停下来给出一个结果。那么,什么时候终止演化输出结果呢?这就要订立一个终止条件,满足这个条件的话程序就输出当前最好的结果并停止。最简单的终止条件就是,如果种群经过了很多代(这里的“很多”是一个需要设定的参数)之后仍然没有显著改变适应性的变异的话,我们就停止并输出结果。我们就用这个终止条件。
好了,现在是万事俱备只欠东风了。定义好基因,写好繁衍、变异、评价适应性、淘汰和终止的代码之后,只需要随机产生一个适当大小的种群,然后让它这样一代代的繁衍、变异和淘汰下去,到最后终止我们就会获得一个惊喜的结果:(这回是完整的了,图片下的数字表示这个扇贝是第几代中最好的)

怎么样?虽说细节上很欠缺,但是也算是不错了。要不,你来试试用100个透明三角形画一个更像的?就是这样的看上去很简单的模拟演化过程也能解决一些我们这些有智慧的人类也感到棘手的问题。
实际上,在生活和生产中,很多时候并不需要得到一个完美的答案;而很多问题如果要得到完美的答案的话,需要很大量的计算。所以,因为遗传算法能在相对较短的时间内给出一个足够好能凑合的答案,它从问世伊始就越来越受到大家的重视,对它的研究也是方兴未艾。当然,它也有缺点,比如说早期的优势基因可能会很快通过交换基因的途径散播到整个种群中,这样有可能导致早熟(premature),也就是说整个种群的基因过早同一化,得不到足够好的结果。这个问题是难以完全避免的。
其实,通过微调参数和繁衍、变异、淘汰、终止的代码,我们有可能得到更有效的算法。遗传算法只是一个框架,里边具体内容可以根据实际问题进行调整,这也是它能在许多问题上派上用场的一个原因。像这样可以适应很多问题的算法还有模拟退火算法、粒子群算法、蚁群算法、禁忌搜索等等,统称为元启发式算法(Meta-heuristic algorithms)。
另外,基于自然演化过程的算法除了在这里说到的遗传算法以外,还有更广泛的群体遗传算法和遗传编程等,它们能解决很多棘手的问题。这也从一个侧面说明,我们不一定需要一个智能才能得到一个构造精巧的系统。
无论如何,如果我们要将遗传算法的发明归功于一个人的话,我会将它归功于达尔文,进化论的奠基人。如果我们不知道自然演化的过程,我们也不可能在电脑中模拟它,更不用说将它应用于实际了。
向达尔文致敬!

Bonus:如果你看明白了这篇文章,而且你懂英语的话,你自然明白下面这个冷笑话:(来自http://xkcd.com/534/)

Just to make sure you don’t have it maximize instead of minimize.
PS: 这里可以在线做文中的实验,不过听说对IE的支持有问题。还有就是,你最好睡觉前开始“进化”,第二天一早起来看结果:)
下面是我实验的结果:

天气热了,蚊子多了,感觉人有点懒洋洋的,有时无法做到连续性思考。但是,时间不能让它就那样流失掉,于是决定找部小说看,因为我觉得看小说思考的东西要少一些。不过我想看的那部小说我电脑上存的是CHM格式的,用Firefox打开的话,有点问题,直接用chmsee吧,我感觉那白底黑字,那行距真不像我能长时间阅读的。试着解包得到html文件,结果因为编码问题而产生一系列问题(全世界都用UTF8多好:)。最后决定还是自己排吧,因为机子上我有专门做过适合屏幕阅读的样式文件,所以把文本copy进vim,再编译一下花不了多少时间。在后面的查看结果时,我还真郁闷到了,虽然之前有看过《TeX相关软件中文字体嵌入一个存在已久的问题水落石出,兼谈不拘小节的中文字体设计》,但是PDF阅读器方面也是有问题的,也许是为了照顾中文字体的“不拘小节”,不过阅读器的“自作多情”有时会让情况更糟。


先看使用“华文宋体”的情况,上面是xpdf中的图,下面是AdobeReader中的图。显然AdobeReader中效果要好得多,xpdf中笔画太细,特别是在一些笔画的末端。



这次使用“微软雅黑”,在xpdf中的效果最好,笔画均匀清晰,evince中笔画要粗些就显得比较挤,而且感觉比较虚。最下面的是AdobeReader中的效果,完全毁了- -


最后再看英文的情况,字体使用的是系统中的“AlMohanad”,可以看出AdobeReader中的渲染比较重,不过那个下划线就比较可怜了。
屏幕阅读我最喜欢的字体是“微软雅黑”,可偏偏它在AdobeReader中废了,而xpdf的中文书签我又无解。
KeyJnote是一款辅助演示的软件,即用来播放PDF文档或其它一些图片文档,它提供了加强演示效果的一些功能,如翻页动画、探照灯效果,计时等。

原程序中,鼠标的左右键可以控制KeyJnote翻页,但是,同时,鼠标的左右键也有选取区域,取消区域等其它功能。这样,有时就会感觉控制起来不方便,因为一不小心就会出现“意外”的翻页,所以,我就想翻页只用键盘来控制就好了,鼠标左右键不可以控制翻页。
KeyJnote是用python写的,它的源程序只有一个python源文件,使用locate很容易找到它,在我的系统中,它在:
/usr/share/keyjnote/keyjnote.py
直接编辑这个文件,大约在3086行的位置,找到:
dest = GetNextPage(Pcurrent, 1)
改成:
dest = 0
在3112行左右的位置,找到:
TransitionTo(GetNextPage(Pcurrent, -1))
改成:
TransitionTo(0)
这样,鼠标的左右键就没有翻页的控制作用了。
播放PDF时,加一个-e的参数启动KeyJnote,可以“保持文档的矢量性”。
BTW:在sourceforge.net上的KeyJnote项目页好像出了点问题,本来KeyJnote有放出windows下的“编译版”,这个版本同时包含了需要的dll文件,不过二进制的文件你就无法作上述的hack了。这里是对以前KeyJnote项目的镜像。
前面通过Google Data API解决了光靠Email不能解决的标签和插图问题,自然,就想到应该可以插入LaTeX语法的数学公式吧,只是把这些公式转成图片插入就可以了。这中间只是多了一个自动编译并转为图片的过程,至少我之前是这么想的。
但在实际的操作中总有意想不到的问题,我第一次碰到了多线程或者多进程的问题。在之前写一些小东西的时候,是没有涉及过多线程或多进程的需求的,可在这里,去编译tex源文件的时候,它出现了。
最先我直接通过os.system把对tex源文件的编译写到某个函数中,可这样是无法执行的,我猜想应该是os.system还没有执行完,这个函数就返回了,而这个函数一返回,就把里面的os.system直接中断了。后来我用subprocess和threading来处理对tex源文件的编译,执行是没有问题了,但我无法在编译tex源文件处做阻塞,一阻塞就不能正常编译。不阻塞倒能正常编译,可我后继的操作必须在tex源文件编译完毕后才能进行,不能并发执行的。
最后这个问题我还是无解,我想可能与python是作为vim的脚本执行有关,这时python执行的这个进程与vim的进程的关系?所以我不得不把原本应该在函数内完成的事放到外部完成,虽然很dirty,但它能正常工作了。
import vim,os,markdown2,re,datetime reInLineMath = re.compile(r'\$.*?\$') reBlockMath = re.compile(r'\\\[.*?\\\]', re.S) def getFileName(): 'get a random filename like 20090423' d = datetime.date.today().strftime('%Y%m%d') return d def createTexFile(body, mathInLineList, mathBlockList): mathInLineList = '\n\\newpage\n'.join(mathInLineList) mathBlockList = '\n\\newpage\n'.join(mathBlockList) texcode = ''' \\documentclass{article}\n \\usepackage{tikz}\n \\usepackage{amsmath}\n \\pagestyle{empty}\n \\\begin{document} %s\n\\newpage\n%s\n \\end{document}''' % (mathInLineList, mathBlockList) file = open('/home/zys/temp/%s.tex' % getFileName(),'w') print >> file,texcode file.close() return file.name subject = vim.current.buffer[0] body = '\n'.join(vim.current.buffer[2:]) mathInLineList = reInLineMath.findall(body) mathBlockList = reBlockMath.findall(body) if mathInLineList.__len__() > 0 or mathBlockList.__len__() > 0: texFile = createTexFile(body, mathInLineList = mathInLineList, mathBlockList = mathBlockList) os.system('rxvt -e pdflatex --output-directory=/home/zys/temp/ %s' % texFile) os.system('rxvt -e convert -trim -density 120 -antialias %s.pdf %s. jpg' % (texFile.split('.')[0],texFile.split('.')[0])) mathList = mathInLineList + mathBlockList if mathList.__len__() == 1: body = body.replace(mathList[i], '' % (texFile.split('.')[0])) else: for i in range(mathList.__len__()): body = body.replace(mathList[i], '' % (texFile.split('.')[0], i))
主要的代码就这些,用正则表达式从正文中取出tex相关的数学公式,然后把这些公式做成一个单独的tex源文件,一页一个公式,编译后得到一个pdf文件,用convert去把这个pdf文件转成jpg图片,这里带一个-trim参数,得到没有边距的图。如果是多页会得到一组编号的jpg图,再回头用这些图的本机地址去替换正文中的tex数学公式。
另外,代码高亮是通过highlight来做的,在vim中选中代码块,执行highlight就可以得到内嵌css的html带pre标签的代码。
下面纯属演示数学公式效果- -
八卦传播问题
假设某地区的总人口为
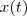




求解得:

于是有:

此表明随时间的增长,消息慢慢地会淡化,逐步被人遗忘。
参考
在<我的博客解决方案>中,最后有一些待解决的问题,昨天看了下Google Date API,算是解决了(主要是插图和标签的问题)。
标签问题
标签使用Blogger Data API是比较好搞定的,本身就有一个AddLabel函数。import gdata.blogger.service import atom def postBlog(subject=None, body=None, labels=None, account=None, password=None): 'to post blog via GData Blogger API' print 'To Post ...' client = gdata.blogger.service.BloggerService() client.ssl = True post = gdata.blogger.BlogPostEntry() post.title = atom.Title(text = subject) post.content = atom.Content(content_type = 'html', text = body) #post.AddLabel('Computer') if labels[0]: map(post.AddLabel, labels) try: client.ClientLogin(account, password) except gdata.service.BadAuthentication: print account, password print "ERROR: Login failed!!. (Wrong username/password?)" return False try: BLOG_ID = client.Get('/feeds/default/blogs').entry[0]. GetSelfLink().href.split('/')[-1] except: print "ERROR: Can not get the BLOG_ID!!" return False try: client.AddPost(post, blog_id = BLOG_ID) except: print "ERROR: Can not add the blog!!" print "Is the format all right?" return False print "Blog `%s` post successfully." % subject2
注意,使用Blogger的API时,一定要使用安全链接(ssl = True),否则是接不上的。传说与GFW有关,昏!
插图问题
插图的问题是这样解决的:
- 通过正则表达式,从正文中获取所有插图的本地地址。
- 把这些图片通过Picasa Web Albums Data API上传到我的Picasa中指定的相册。
- 获取上传后,在Picasa中的这些图片的URL。
- 把正文中,所有图片的本地地址替换成Picasa中的URL。
-
import gdata.photos.service import gdata.media import gdata.geo def uploadImages(filelist, account, password): '''Upload all images. And thd filelist is the re.findall() in blog.''' print "Upload All Images ..." try: gd_client = gdata.photos.service.PhotosService() gd_client.email = account gd_client.password = password gd_client.source = 'zys-blogimage-1' gd_client.ProgrammaticLogin() except: print 'ERROR: Could not Login in Picasa!!' return False album = gd_client.GetUserFeed().entry[1] album_url = '/data/feed/api/user/%s/albumid/%s' % (account, album.gphoto_id.text) replaceList = [] for f in filelist: print "Uploading `%s` ..." % f[1] try: photo = gd_client.InsertPhotoSimple(album_url, getFileName(), f[0], f[1], content_type='image/j peg') except: print 'ERROR: upload %s failed!!' % f[1] return False replaceList.append((f[1], photo.GetMediaURL())) print "Completed. --> `%s`" % photo.GetMediaURL() print "All images have Uploaded." return replaceList
整理一下思绪,把当初的想法记录一下。
问题描述
建立一个博客发布平台,以便分享和记录自己的一些想法。
功能需求
- 在页面布局上基本兼容各种浏览器。
- 在页面主题上简洁、或可以让我完全自定义。
- RSS完全供稿。
- 自动投递,使我第一时间获取评论内容。
- 二级域名。
- 可以使用通用接口发布文章,Email或单独的API。
- 可以最大限度控制文章的格式,或直接支持使用HTML。
- 文章的保存有保证。
- 我可以用VIM写文章。
- 具备一定的分类管理功能。
- 访问速度不能太慢。
理想方案
打开VIM,写东西,发送。(自动发表、分类存档、备份源文件)
自己开发还是使用现成的?
自己开发的好处我可以完全控制所有的环节,随意添加我需要的功能,花点钱还能弄个顶级域名。但代价是,要花费比较多的时间,还要每年投入个几百元的主机费用。还有以后系统升级时可能非常折腾。而我现在又没很多的时间也没有钱,所以还是用一个现成的好。
用现成的我就选了Blogger。
实现方案
在VIM中如何发送?
一个比较通用方式是,在本机架设一个SMTP服务器,然后使用一个可以用VIM作编辑器的客户端,写好内容后本地投递。但这种方式太麻烦了,不但要一个独立的SMTP服务器,而且在写东西时你实际上还需要去打开一个客户端。
最简单的方式应该感谢gmail的开放API。因为gmail有开放的API,所以你使用这个API甚至可以把你的gmail账户当成是一个SMTP服务器。还有一个关键的因素就是,gmail有python的API,而VIM的脚本中是可以直接嵌入python的。剩下的事就比较简单了。
首先,从http://libgmail.sourceforge.net/下载libgmai。
在VIM中使用libgmail直接发送邮件到指定地址(参考: http://djcraven5.blogspot.com/2006/10/send-gmail-message-from-vim.html):
" Make sure the Vim was compiled with +python before loading the
script...
if !has("python")
finish
endif
:command! -nargs=? GMSend :call GMailSend("<args>")
function! GMailSend(args)
python << EOF
import vim
to = vim.eval('a:args')
GSend(to)
EOF
endfunction
python << EOF
########### BEGIN USER CONFIG ##########
account = 'xxxx@gmail.com'
password = 'xxxxx'
########### END USER CONFIG ###########
def GSend(to):
"""
Send the current buffer as a Gmail message to a given user.
"""
import libgmail
subject = vim.current.buffer[0]
attachments = vim.current.buffer[2].split(',')
if attachments[0] == 'None': attachments = None
body = '\n'.join(vim.current.buffer[4:])
ga = libgmail.GmailAccount(account, password)
try:
ga.login()
except libgmail.GmailLoginFailure:
print account, password
print "Login failed!!. (Wrong username/password?)"
gmsg = libgmail.GmailComposedMessage(to, subject, body, filenames
= attachments)
result = ga.sendMessage(gmsg)
if result:
print "Message sent `%s` successfully." % subject
else:
print "Could not send message."
EOF
格式如何控制?
Blogger中可以直接使用HTML,所以直接发送HTML格式的邮件就可以了。
但是,如果直接写HTML不是太折腾了吗?所以我想用一种wiki的语法来写,然后解析成HTML后发送出去。最先考虑的是用与MoinMoin一样的语法,不过MoinMoin中似乎并没有把它的语法parser分离出来,google了一下,也有人对此进行了相关的探索,但我没找到比较圆满的结果。于是我决定使用markdown,它比较简单,网上相关的扩展实现也不少,使用面还是很广的,重要的是它有python的实现,可以从这里下载(http://pypi.python.org/pypi/markdown2/)。
markdown2只有一个文件,使用非常简单:
>>> import markdown2
>>> markdown2.markdown('*syntax*')
u'<p><em>syntax</em></p>\n'
>>>
要在VIM中正常使用markdown2解析后的结果,需要对结果进行一次utf8的编码。
body = markdown2.markdown(body).encode('utf8')
然后对于解析后得到的HTML结果,可以先生成一个本机的临时文件,在本地浏览器中预览一下。
file = open('/home/zys/temp/' + subject + '.html','w')
print >> file,body
file.close()
cmd = 'firefox /home/zys/temp/%s.html' % subject
os.system(cmd)
备份源文件
每一篇文章的markdown2格式的源文件,都在发布文章的同时发送到我指定的邮箱当中保存。
file = open('/home/zys/temp/' + subject + '.markdown', 'w')
print >> file,source
file.close()
if not attachments: attachments = []
attachments.append('/home/zys/temp/' + subject + '.markdown')
gmsg2 = libgmail.GmailComposedMessage('xxxxx@gmail.com',
'[带着梦想走天涯]' + subject, body, filenames = attachments)
TODO
经过上面提到一番折腾后,已经可以比较顺手地使用了,但还有一些比较麻烦的问题还没有解决。
在文章中插图。这点的麻烦之处在于自动上传图片。如果在邮件当中添加图片附件,那么这些图片会被自动上传到picasa中,同时自动在文章的最前面插入这些图片,只是最前面,你不能把它插入到文章的其它部分中。如果在文章中间手动使用HTML标签插入图片,那么需要自己先将图片上传,获得URL后才能进一步操作。其实在gmail中已经可以自由插图,系统会自动上传,但在本机的VIM中,如何在邮件中自由插图我还无解T_T。这个在文章中间插图的需求还影响到其它一些功能的实现,如使用LaTeX的语法写一些公式或画一些图,本来可以自动转成图片插入到HTML页面中的。
为文章添加标签。很遗憾,通过邮件方式发布文章,我就是不知道怎么添加标签,google也无结果。
markdown2的hack。把markdown2改成尽量接近MoinMoin的语法,还要给它添加表格的相关语法,因为直接用HTML写一个表格还是比较烦的。
结束语
反正现在使用这个解决方案还是可以说比较顺手的。接下来会去看一下Blogger Data API,看能不能解决存在的问题。



事件本身很简单,在全运会的滑冰比赛中一位名为:"陈沛佟"的很擅长三周半接三周半的89年生的且是某群中女性公认"蛮帅的耶!"这么一人物,在赛场上爆了种子了……
此人身着种以及种命中男主角――基拉大和的全套制服,在SEED的背景音乐的帮衬下获得了全场最高分!
期待他能在冬奥会上尽显"亚洲宅风"!
今天又去找食堂卖卤肉的师傅谈话了,因为我吃的鸡腿像是在加葱的白水中泡过一样,与以前的味道大不相同,而我吃了两口实在郁闷了。交谈两句后,那师傅很快明白问题所在--卤水加错了。我是说那里面怎么还会有葱。旁边的那位"新手",也是肇事者,估计心里在嘀咕着"吃什么不一样吃,哪来那么多讲究。"当然,如果那个窗口是这位"新手"负责的话,肯定早就"隔儿皮"了,不可能是现在的"忙不过来还要叫人帮忙"。
这种"会拿锅铲就敢开馆子"的"新手",这里很多,以我一个四川人的嘴巴来说的话。一般我都会选人少的时间段去食堂吃饭,我要是看到那个卖卤肉的窗口是其它人在"主刀"的话,我是不会去买的,我怕一块肉被切得比砖块还厚。但话又说回来,如果味道上有什么问题,我也会去给那个师傅说,他也会接受正确的意见。所以,一直以来,在学校我还能找到一点点吃的东西。
这种讲究,能让你在一些枯燥的事中,找到一些乐趣(吃饭显然是一件枯燥的事)。
以前在文印店做兼职时,除了用LaTeX做论文录入这类技术活儿,还有复印这种体力活。即使是体力活,我做得还是很开心的。每当开始复印一本书时,都要设计一套方案:要设置好输入尺寸,输出尺寸,输出方式,输出纸张,还要让翻页和放置源稿的动作尽量简单以提高效率。之后还要用厚纸做一个封面,再是刷胶、上钉、裁切。我的要求是:页面要填充均匀,边距合适,没有黑边。这可不是把书放上去,按一下按钮就可以满足的要求。每本书都有它具体需要解决的难题,有时我需要去翻一体机的说明书,有时还要想一些方法hack,对我而言,它就不再是枯燥的体力活儿了:)
我对吃的东西挑剔,是因为我知道什么是好吃;那位师傅肯听我说,也是因为他知道什么是好吃。我对复印出来的文档挑剔,是因为我知道TeX可以做出多么高质的文档。
有人说写代码的人都是理想主义者,嗯,在这个浮躁的社会里,理想主义者才能体会到更多的乐趣吧。

晚上把<樱花大战3~巴黎在燃烧>打完了,这个2001年的游戏,我从装上到打完用了有五个月时间吧,虽然最后的游戏时间显示只有16个多小时。
日常点点滴滴的细节,总有很多让人感动的地方,上次看一个节目在介绍广井王子时,就说他善于把握生活中让人感动的细节,这点,在<樱花大战>系列中有很好的体现。
静下心来,慢慢地去体会游戏中想要传达的那个世界,经典的日式游戏都有这种感觉,也是因为这个,才使得经典不会随着时间的流逝而失去它的光辉。
在游戏的最后的STAFF中,看到了一个致谢:DC版<樱花大战>制作组……,不知为什么感到了一点点的悲凉,DC已经不在了,也不知道自己还有多少机会能静静地去体会一款游戏啊,毕竟,这是个浮躁的社会。
希望有机会能继续把<樱花大战4>打通,不过我下一个装在机子上的游戏是<阿玛迪斯战记>,曾经的汉堂啊~~
回学校后,第二天上街,随便就到电信营业部去,想把以前用的小灵通注销了。不过电信的规矩还真�。
首先你要交清欠费。这点没什么说的,虽然我几个月没用,但是在我注销之前,每月的基本费我也认为是应该支付的。不过,交清欠费之后,再让我交100元的预存!说是这个月的话费,系统还没有统计出来,所有你要预存,月后你来多退少补。
这样的规定,估计只有在和谐的中国才会存在- -
注销号码后,和电信就没有服务上的关系了,为什么还在交钱给你?无法统计出当前的即时话费,是你自己系统的问题,关消费者P事。就算是这个月的话费还没有支付,那又为什么不是下个月让消费者来"补",而偏偏要让消费者预存,来个"多退少补"。
当然,最后我拿回我的身份证,也没有注销那个号码,同时欠费也一分没给,我也永远也不会给了。
回来在公交车上了多想了一下,这笔欠费对电信来说还是相当有用的吧。你是否会支付对于电信来说没有什么关系,你永远不支付它也不在乎,反正在它的账面上会记着的。这笔坏账,在对国家的合理避税,对投资者的财务报表上就有操作的空间咯,过个几年,电信报表上来个亏损都不稀奇。
原副部级官员王益不识谱却被誉天才音乐家
http://news.163.com/09/0403/03/55UQL6E10001124J.html
评论:
你若到了那级干部也有人捧你,信不?
官当到一定级别,字都不会写也能成博士你信不?就看你想不想
卧槽,不知道是哪个王八蛋放的种子,下个通宵下了整部葫芦娃
网易网友太有才了,笑死我了。

上周,连载了有两年的<GUNDAM OO>在第二季的25集划下了句号。我个人的总体感觉一般般,当然,这其中包括它分成两季播放的给人一种不连贯感。但更多的,是认为它着眼于一个大局的概念,而没有刻画好细节。
中心的线索是GUNDAM系列一贯的,比较正统的"人类的进化",这次说的大义点,就是"相互理解,共同进步",这就是人类的"变革"。这部作品对于这一点还是表现得比较圆满,也交织着观点的冲突:
- 变革者统治人类与变革者引导人类。
- 有目的的战争与没有目的的战争。
- 和平的方式让人类相互理解与战争的方式让人类相互理解。
等等。
这部作品在画面,场景,音乐方面等都不失"高达水准",但在人物刻画上就比较差强人意了。
一开始就弄出了四个主角,还四个都是男的,这个场子铺大了。四人中,除了刹那与"伪娘",另外两个就有龙套的感觉,去掉这两人,对整个情节没有任何影响。但事实上,这两个人是有文章可以做的,可阿勒路亚的双重人格,洛克昂的亲兄弟间的关系这些都只是点到为止,都没有深入。其它"迷一样"的角色也太多了,刚出来的三小强,王留美及其它一些的所谓的观察者,还世代的宿命哦。还有那个沙兹的姐姐不是被什么人做掉了吗。很多东西都没有交代清楚。
另外,刹那最终也没有推倒玛莉娜,相信让很多人都失望了。
再说机体,这次数量有了,组合系,变形系,"酸浆果",MA,连RX-78都有。但对我而言确实没什么意外的惊喜,后面更变成OO-Raiser的单机秀了,反正它是无敌的,经典的"裸聊系统"也有。嗯,怎么说呢,不是这些机体设计的不好,没有出现在合适的位置的感觉。
算了算了,细细去剖析,我没那种宅情调。对于一部作品,更多是想它让我们记住了什么,这也是我认为最客观的标准,不过很可惜,这部作品似乎并没有让我记住什么场景,硬要说的话,就是最后一幕那个结婚的幸运儿吧。话又说回来,上一部的SEED我倒是有很多记忆:
- 拉克丝把Freedom交给基拉的那一幕。
- <从天而降的剑>那话,伴随着那首<Meteor>。
- 卡嘉丽的父亲自爆奥布,自由和正义在穿梭机上,<晓之车>奏响。
- 巴基露露叫大天使号发射阳电子破城炮的那一幕。
- 穆挡在大天使号前那一幕。
- ……
在OO连载间还看了两部TV动画,<叛逆的鲁鲁修>和<超时空要塞:边境>,这三部动画中个人评价最高的是MACROSS F。
2010年的OO剧场版……
话说,高达OO一完,就没什么看的了,有一种绝粮的感觉- -,4月要开始<钢之炼金术士>,我先去把第一部补了。


随着Web2.0概念的不断推广,许多应用都在寻求web化的解决方案,我们打开一个浏览器,可能做更多的事了。我现在的观念是,浏览器能做的,就不让独立应用程序做。说实话,Firefox的启动速度真的很尴尬,不过好在我是开机把它打开就一直不关它了,而又因为我有三个虚拟桌面,所有它放在那里一点也不碍事,要使用时瞬间就切换过去了。既然要经常性地使用浏览器,当然要把它打造得得心应用手咯,以下是我使用的Firefox插件。
下面介绍的插件,按名字google一下就可以在Mozilla的网站上找到安装地址。
Tab Mix Lite CE
这是一个轻量级的标签扩展,提供的功能不多,但够我用了。它可以让我设置在新标签中打开收藏夹及标签上的鼠标操作等。
Vimperator
它的功能是,可以让Firefox的操作像VIM中的那样。不过,我只是用它把我的Firefox界面变得更简洁一点,操作上一般只使用打开新页t,其它我不会像VIM中那样去弄的。
It's All Text!
它的功能很简单,让你可以调用你喜欢的外部编辑去编辑网页中<textarea>的内容。现在网页中那些长段的东西,比如写wiki我都可以按一下F2然后调用VIM来处理了^o^
Zotero
这东西自称是一个文献管理工具?不过我不用来做文献管理,在方面我有更好的选择。我只使用Zotero来快速收藏网页(保存网页快照),比如准考证信息之类的。或用来快速保存网页中的图片:比如一个网页中有几十张你喜欢的图片,你不会一张一点"另存之"吗?直接保存快照你就可以在相关文件夹把这些图片拷贝出来了。
Flashblock
因为一旦碰到多嵌了几个Flash的网页,我的CPU的风扇就会狂转。这点让我很不爽,并且那些嵌入的Flash多是对我无用的广告。使用Flashblock就比较清静了,它会屏掉页面上的所有Flash内容,事实上这些Flash上会添加一个图标,你点击一下就可以查看这个Flash了,所以上youtube,youku不会有麻烦,至少我认为相对于那些广告,在这些视频上多点一下是值得的。
CHM Reader
这个扩展让你的Firefox可以打开CHM文档,当然,作为一个阅读器或许不会让你感兴趣,我感兴趣的是,在CHM档中,你可以像在普通网页中那样保存书签。
Gb2Big
把繁体中文转成简体的扩展,至少可以转换大部分。繁体字虽然看得懂,不过毕竟没有简体字那么感觉自然嘛。
MediaWrap
它的功能说是让Firefox播放网页中嵌入的媒体,比如使用<embed>嵌入的那些东西,但我使用的机会似乎不是很多。
Gmail Manager
有了它,我不用再打开页面去查看我是否有新邮件了。它会自动去检查我的邮箱,并在右下角提示我邮箱的状况和新邮件的信息摘要。
Firebug
这是相当牛X的一个扩展,主要用于HTML,CSS,Javascript的调试。对于你查看的网页,可以使用Firebug方便在查看它的源代码,并做修改,修改的结果直接在页面上反映出来(当然这个修改是不可能会被保存的)!
Music Play Minion
一个MPD的前端。前面说过,我想让浏览器做更多的事,显然,作为一个C/S架构的音频播放软件,在Firefox中控制它并不是我一个人有这样的需求。而且我觉得它的界面设计得也不错:-),见第二张图。
Greasemonkey
Firefox的用户脚本管理器,使用它,用户就可以自定义一些脚本用与浏览的网页上。在Google Reader中进行RSS全文变换要使用到它。
最后,感谢那些为Firefox贡献插件的人。
嗯,要毕业了,觉得有些思绪还是有记录下来的必要的,再加上对我来说的很多"要求"也基本具备了,所以就在blogger上开了一个博客。
其实事博客这玩意儿对我来说一直是一个结啊。
2005年的时候,我在blogcn上建了一个,想是要记录一些东西,可以后来觉得要打那么多字实在是太累了(那时我还用智能ABC),加上那访问速度确实不怎么样。于是那个页面就沉睡在那里了。不过它的图片管理我倒是一直在用,用来保存BBS的头像之类的图,因为可以外链的嘛。
后来国内的各大门户网站都开始提供BLOG服务,我嘛就开始了又一轮的选择。那时我平时一般都在用Firefox了,所以要求也很简单,博客的页面兼容Firefox、访问速度不慢,不过不知道是我时机选择的不好,还是其它什么RP出问题了。轮寻一番下来我都不满意。还记得当时Sohu的BLOG页面在FF上完全无解(- -|| 可能是博主自定义页面的问题),163的页面我整死打不开。
2007年的时候,我尝试了blogspot,除了访问速度慢了一点(但比较稳定),其它我感觉都很好了:很自由的模块设置、RSS订阅、与gmail账户的集成等,特别是它的邮件发表功能给我留下了很深的印象。不过说来也巧,我把BLOG页面弄好没几天,blogspot又一次被国内和谐掉了。
之后,我就想,现成的满意的找不到,我只能自己给自己做了。当时只是想,我还没那能力。于是这事就暂时搁那里了。
前段时间把论文的事弄完后,又开始思考这个问题。不同的是,现在我要搭建一个BLOG系统是轻而易举的事情(django的宣传是十分钟,我们这些新手一个小时总能搞定吧),可论文项目的经历让我领略了google各服务集成化的超强威力,而且它还提供了API供二次开发,blogspot似乎也不在GFW的黑名单之列了,我何必再去重复造车轮嘛,每年还不用给域名费和空间租金。
ctrl+F2 run VIM
to write sth
with command ':Blog' to post it
我想要就是这个,那种打开网页,登陆的方式会让我的思绪不连贯。
博客上的文章都会抄送到我的QQ邮箱,我会不定时地把它们转发到Qzone(关于这点,虽然Qzone支持从QQ mail发表,但邮件是无法通过'自动转发'的方式发到Qzone的,至少我尝试没有成功),但以后我想我都会把开QQ mail的时间节约下来去玩游戏的^o^
最后,博客这东西,我强烈推荐大家使用Google Reader进行订阅阅读。