

前面通过Google Data API解决了光靠Email不能解决的标签和插图问题,自然,就想到应该可以插入LaTeX语法的数学公式吧,只是把这些公式转成图片插入就可以了。这中间只是多了一个自动编译并转为图片的过程,至少我之前是这么想的。
但在实际的操作中总有意想不到的问题,我第一次碰到了多线程或者多进程的问题。在之前写一些小东西的时候,是没有涉及过多线程或多进程的需求的,可在这里,去编译tex源文件的时候,它出现了。
最先我直接通过os.system把对tex源文件的编译写到某个函数中,可这样是无法执行的,我猜想应该是os.system还没有执行完,这个函数就返回了,而这个函数一返回,就把里面的os.system直接中断了。后来我用subprocess和threading来处理对tex源文件的编译,执行是没有问题了,但我无法在编译tex源文件处做阻塞,一阻塞就不能正常编译。不阻塞倒能正常编译,可我后继的操作必须在tex源文件编译完毕后才能进行,不能并发执行的。
最后这个问题我还是无解,我想可能与python是作为vim的脚本执行有关,这时python执行的这个进程与vim的进程的关系?所以我不得不把原本应该在函数内完成的事放到外部完成,虽然很dirty,但它能正常工作了。
import vim,os,markdown2,re,datetime reInLineMath = re.compile(r'\$.*?\$') reBlockMath = re.compile(r'\\\[.*?\\\]', re.S) def getFileName(): 'get a random filename like 20090423' d = datetime.date.today().strftime('%Y%m%d') return d def createTexFile(body, mathInLineList, mathBlockList): mathInLineList = '\n\\newpage\n'.join(mathInLineList) mathBlockList = '\n\\newpage\n'.join(mathBlockList) texcode = ''' \\documentclass{article}\n \\usepackage{tikz}\n \\usepackage{amsmath}\n \\pagestyle{empty}\n \\\begin{document} %s\n\\newpage\n%s\n \\end{document}''' % (mathInLineList, mathBlockList) file = open('/home/zys/temp/%s.tex' % getFileName(),'w') print >> file,texcode file.close() return file.name subject = vim.current.buffer[0] body = '\n'.join(vim.current.buffer[2:]) mathInLineList = reInLineMath.findall(body) mathBlockList = reBlockMath.findall(body) if mathInLineList.__len__() > 0 or mathBlockList.__len__() > 0: texFile = createTexFile(body, mathInLineList = mathInLineList, mathBlockList = mathBlockList) os.system('rxvt -e pdflatex --output-directory=/home/zys/temp/ %s' % texFile) os.system('rxvt -e convert -trim -density 120 -antialias %s.pdf %s. jpg' % (texFile.split('.')[0],texFile.split('.')[0])) mathList = mathInLineList + mathBlockList if mathList.__len__() == 1: body = body.replace(mathList[i], '' % (texFile.split('.')[0])) else: for i in range(mathList.__len__()): body = body.replace(mathList[i], '' % (texFile.split('.')[0], i))
主要的代码就这些,用正则表达式从正文中取出tex相关的数学公式,然后把这些公式做成一个单独的tex源文件,一页一个公式,编译后得到一个pdf文件,用convert去把这个pdf文件转成jpg图片,这里带一个-trim参数,得到没有边距的图。如果是多页会得到一组编号的jpg图,再回头用这些图的本机地址去替换正文中的tex数学公式。
另外,代码高亮是通过highlight来做的,在vim中选中代码块,执行highlight就可以得到内嵌css的html带pre标签的代码。
下面纯属演示数学公式效果- -
八卦传播问题
假设某地区的总人口为
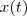




求解得:

于是有:

此表明随时间的增长,消息慢慢地会淡化,逐步被人遗忘。
参考
在<我的博客解决方案>中,最后有一些待解决的问题,昨天看了下Google Date API,算是解决了(主要是插图和标签的问题)。
标签问题
标签使用Blogger Data API是比较好搞定的,本身就有一个AddLabel函数。import gdata.blogger.service import atom def postBlog(subject=None, body=None, labels=None, account=None, password=None): 'to post blog via GData Blogger API' print 'To Post ...' client = gdata.blogger.service.BloggerService() client.ssl = True post = gdata.blogger.BlogPostEntry() post.title = atom.Title(text = subject) post.content = atom.Content(content_type = 'html', text = body) #post.AddLabel('Computer') if labels[0]: map(post.AddLabel, labels) try: client.ClientLogin(account, password) except gdata.service.BadAuthentication: print account, password print "ERROR: Login failed!!. (Wrong username/password?)" return False try: BLOG_ID = client.Get('/feeds/default/blogs').entry[0]. GetSelfLink().href.split('/')[-1] except: print "ERROR: Can not get the BLOG_ID!!" return False try: client.AddPost(post, blog_id = BLOG_ID) except: print "ERROR: Can not add the blog!!" print "Is the format all right?" return False print "Blog `%s` post successfully." % subject2
注意,使用Blogger的API时,一定要使用安全链接(ssl = True),否则是接不上的。传说与GFW有关,昏!
插图问题
插图的问题是这样解决的:
- 通过正则表达式,从正文中获取所有插图的本地地址。
- 把这些图片通过Picasa Web Albums Data API上传到我的Picasa中指定的相册。
- 获取上传后,在Picasa中的这些图片的URL。
- 把正文中,所有图片的本地地址替换成Picasa中的URL。
-
import gdata.photos.service import gdata.media import gdata.geo def uploadImages(filelist, account, password): '''Upload all images. And thd filelist is the re.findall() in blog.''' print "Upload All Images ..." try: gd_client = gdata.photos.service.PhotosService() gd_client.email = account gd_client.password = password gd_client.source = 'zys-blogimage-1' gd_client.ProgrammaticLogin() except: print 'ERROR: Could not Login in Picasa!!' return False album = gd_client.GetUserFeed().entry[1] album_url = '/data/feed/api/user/%s/albumid/%s' % (account, album.gphoto_id.text) replaceList = [] for f in filelist: print "Uploading `%s` ..." % f[1] try: photo = gd_client.InsertPhotoSimple(album_url, getFileName(), f[0], f[1], content_type='image/j peg') except: print 'ERROR: upload %s failed!!' % f[1] return False replaceList.append((f[1], photo.GetMediaURL())) print "Completed. --> `%s`" % photo.GetMediaURL() print "All images have Uploaded." return replaceList
整理一下思绪,把当初的想法记录一下。
问题描述
建立一个博客发布平台,以便分享和记录自己的一些想法。
功能需求
- 在页面布局上基本兼容各种浏览器。
- 在页面主题上简洁、或可以让我完全自定义。
- RSS完全供稿。
- 自动投递,使我第一时间获取评论内容。
- 二级域名。
- 可以使用通用接口发布文章,Email或单独的API。
- 可以最大限度控制文章的格式,或直接支持使用HTML。
- 文章的保存有保证。
- 我可以用VIM写文章。
- 具备一定的分类管理功能。
- 访问速度不能太慢。
理想方案
打开VIM,写东西,发送。(自动发表、分类存档、备份源文件)
自己开发还是使用现成的?
自己开发的好处我可以完全控制所有的环节,随意添加我需要的功能,花点钱还能弄个顶级域名。但代价是,要花费比较多的时间,还要每年投入个几百元的主机费用。还有以后系统升级时可能非常折腾。而我现在又没很多的时间也没有钱,所以还是用一个现成的好。
用现成的我就选了Blogger。
实现方案
在VIM中如何发送?
一个比较通用方式是,在本机架设一个SMTP服务器,然后使用一个可以用VIM作编辑器的客户端,写好内容后本地投递。但这种方式太麻烦了,不但要一个独立的SMTP服务器,而且在写东西时你实际上还需要去打开一个客户端。
最简单的方式应该感谢gmail的开放API。因为gmail有开放的API,所以你使用这个API甚至可以把你的gmail账户当成是一个SMTP服务器。还有一个关键的因素就是,gmail有python的API,而VIM的脚本中是可以直接嵌入python的。剩下的事就比较简单了。
首先,从http://libgmail.sourceforge.net/下载libgmai。
在VIM中使用libgmail直接发送邮件到指定地址(参考: http://djcraven5.blogspot.com/2006/10/send-gmail-message-from-vim.html):
" Make sure the Vim was compiled with +python before loading the
script...
if !has("python")
finish
endif
:command! -nargs=? GMSend :call GMailSend("<args>")
function! GMailSend(args)
python << EOF
import vim
to = vim.eval('a:args')
GSend(to)
EOF
endfunction
python << EOF
########### BEGIN USER CONFIG ##########
account = 'xxxx@gmail.com'
password = 'xxxxx'
########### END USER CONFIG ###########
def GSend(to):
"""
Send the current buffer as a Gmail message to a given user.
"""
import libgmail
subject = vim.current.buffer[0]
attachments = vim.current.buffer[2].split(',')
if attachments[0] == 'None': attachments = None
body = '\n'.join(vim.current.buffer[4:])
ga = libgmail.GmailAccount(account, password)
try:
ga.login()
except libgmail.GmailLoginFailure:
print account, password
print "Login failed!!. (Wrong username/password?)"
gmsg = libgmail.GmailComposedMessage(to, subject, body, filenames
= attachments)
result = ga.sendMessage(gmsg)
if result:
print "Message sent `%s` successfully." % subject
else:
print "Could not send message."
EOF
格式如何控制?
Blogger中可以直接使用HTML,所以直接发送HTML格式的邮件就可以了。
但是,如果直接写HTML不是太折腾了吗?所以我想用一种wiki的语法来写,然后解析成HTML后发送出去。最先考虑的是用与MoinMoin一样的语法,不过MoinMoin中似乎并没有把它的语法parser分离出来,google了一下,也有人对此进行了相关的探索,但我没找到比较圆满的结果。于是我决定使用markdown,它比较简单,网上相关的扩展实现也不少,使用面还是很广的,重要的是它有python的实现,可以从这里下载(http://pypi.python.org/pypi/markdown2/)。
markdown2只有一个文件,使用非常简单:
>>> import markdown2
>>> markdown2.markdown('*syntax*')
u'<p><em>syntax</em></p>\n'
>>>
要在VIM中正常使用markdown2解析后的结果,需要对结果进行一次utf8的编码。
body = markdown2.markdown(body).encode('utf8')
然后对于解析后得到的HTML结果,可以先生成一个本机的临时文件,在本地浏览器中预览一下。
file = open('/home/zys/temp/' + subject + '.html','w')
print >> file,body
file.close()
cmd = 'firefox /home/zys/temp/%s.html' % subject
os.system(cmd)
备份源文件
每一篇文章的markdown2格式的源文件,都在发布文章的同时发送到我指定的邮箱当中保存。
file = open('/home/zys/temp/' + subject + '.markdown', 'w')
print >> file,source
file.close()
if not attachments: attachments = []
attachments.append('/home/zys/temp/' + subject + '.markdown')
gmsg2 = libgmail.GmailComposedMessage('xxxxx@gmail.com',
'[带着梦想走天涯]' + subject, body, filenames = attachments)
TODO
经过上面提到一番折腾后,已经可以比较顺手地使用了,但还有一些比较麻烦的问题还没有解决。
在文章中插图。这点的麻烦之处在于自动上传图片。如果在邮件当中添加图片附件,那么这些图片会被自动上传到picasa中,同时自动在文章的最前面插入这些图片,只是最前面,你不能把它插入到文章的其它部分中。如果在文章中间手动使用HTML标签插入图片,那么需要自己先将图片上传,获得URL后才能进一步操作。其实在gmail中已经可以自由插图,系统会自动上传,但在本机的VIM中,如何在邮件中自由插图我还无解T_T。这个在文章中间插图的需求还影响到其它一些功能的实现,如使用LaTeX的语法写一些公式或画一些图,本来可以自动转成图片插入到HTML页面中的。
为文章添加标签。很遗憾,通过邮件方式发布文章,我就是不知道怎么添加标签,google也无结果。
markdown2的hack。把markdown2改成尽量接近MoinMoin的语法,还要给它添加表格的相关语法,因为直接用HTML写一个表格还是比较烦的。
结束语
反正现在使用这个解决方案还是可以说比较顺手的。接下来会去看一下Blogger Data API,看能不能解决存在的问题。



事件本身很简单,在全运会的滑冰比赛中一位名为:"陈沛佟"的很擅长三周半接三周半的89年生的且是某群中女性公认"蛮帅的耶!"这么一人物,在赛场上爆了种子了……
此人身着种以及种命中男主角――基拉大和的全套制服,在SEED的背景音乐的帮衬下获得了全场最高分!
期待他能在冬奥会上尽显"亚洲宅风"!
今天又去找食堂卖卤肉的师傅谈话了,因为我吃的鸡腿像是在加葱的白水中泡过一样,与以前的味道大不相同,而我吃了两口实在郁闷了。交谈两句后,那师傅很快明白问题所在--卤水加错了。我是说那里面怎么还会有葱。旁边的那位"新手",也是肇事者,估计心里在嘀咕着"吃什么不一样吃,哪来那么多讲究。"当然,如果那个窗口是这位"新手"负责的话,肯定早就"隔儿皮"了,不可能是现在的"忙不过来还要叫人帮忙"。
这种"会拿锅铲就敢开馆子"的"新手",这里很多,以我一个四川人的嘴巴来说的话。一般我都会选人少的时间段去食堂吃饭,我要是看到那个卖卤肉的窗口是其它人在"主刀"的话,我是不会去买的,我怕一块肉被切得比砖块还厚。但话又说回来,如果味道上有什么问题,我也会去给那个师傅说,他也会接受正确的意见。所以,一直以来,在学校我还能找到一点点吃的东西。
这种讲究,能让你在一些枯燥的事中,找到一些乐趣(吃饭显然是一件枯燥的事)。
以前在文印店做兼职时,除了用LaTeX做论文录入这类技术活儿,还有复印这种体力活。即使是体力活,我做得还是很开心的。每当开始复印一本书时,都要设计一套方案:要设置好输入尺寸,输出尺寸,输出方式,输出纸张,还要让翻页和放置源稿的动作尽量简单以提高效率。之后还要用厚纸做一个封面,再是刷胶、上钉、裁切。我的要求是:页面要填充均匀,边距合适,没有黑边。这可不是把书放上去,按一下按钮就可以满足的要求。每本书都有它具体需要解决的难题,有时我需要去翻一体机的说明书,有时还要想一些方法hack,对我而言,它就不再是枯燥的体力活儿了:)
我对吃的东西挑剔,是因为我知道什么是好吃;那位师傅肯听我说,也是因为他知道什么是好吃。我对复印出来的文档挑剔,是因为我知道TeX可以做出多么高质的文档。
有人说写代码的人都是理想主义者,嗯,在这个浮躁的社会里,理想主义者才能体会到更多的乐趣吧。

晚上把<樱花大战3~巴黎在燃烧>打完了,这个2001年的游戏,我从装上到打完用了有五个月时间吧,虽然最后的游戏时间显示只有16个多小时。
日常点点滴滴的细节,总有很多让人感动的地方,上次看一个节目在介绍广井王子时,就说他善于把握生活中让人感动的细节,这点,在<樱花大战>系列中有很好的体现。
静下心来,慢慢地去体会游戏中想要传达的那个世界,经典的日式游戏都有这种感觉,也是因为这个,才使得经典不会随着时间的流逝而失去它的光辉。
在游戏的最后的STAFF中,看到了一个致谢:DC版<樱花大战>制作组……,不知为什么感到了一点点的悲凉,DC已经不在了,也不知道自己还有多少机会能静静地去体会一款游戏啊,毕竟,这是个浮躁的社会。
希望有机会能继续把<樱花大战4>打通,不过我下一个装在机子上的游戏是<阿玛迪斯战记>,曾经的汉堂啊~~
回学校后,第二天上街,随便就到电信营业部去,想把以前用的小灵通注销了。不过电信的规矩还真�。
首先你要交清欠费。这点没什么说的,虽然我几个月没用,但是在我注销之前,每月的基本费我也认为是应该支付的。不过,交清欠费之后,再让我交100元的预存!说是这个月的话费,系统还没有统计出来,所有你要预存,月后你来多退少补。
这样的规定,估计只有在和谐的中国才会存在- -
注销号码后,和电信就没有服务上的关系了,为什么还在交钱给你?无法统计出当前的即时话费,是你自己系统的问题,关消费者P事。就算是这个月的话费还没有支付,那又为什么不是下个月让消费者来"补",而偏偏要让消费者预存,来个"多退少补"。
当然,最后我拿回我的身份证,也没有注销那个号码,同时欠费也一分没给,我也永远也不会给了。
回来在公交车上了多想了一下,这笔欠费对电信来说还是相当有用的吧。你是否会支付对于电信来说没有什么关系,你永远不支付它也不在乎,反正在它的账面上会记着的。这笔坏账,在对国家的合理避税,对投资者的财务报表上就有操作的空间咯,过个几年,电信报表上来个亏损都不稀奇。
原副部级官员王益不识谱却被誉天才音乐家
http://news.163.com/09/0403/03/55UQL6E10001124J.html
评论:
你若到了那级干部也有人捧你,信不?
官当到一定级别,字都不会写也能成博士你信不?就看你想不想
卧槽,不知道是哪个王八蛋放的种子,下个通宵下了整部葫芦娃
网易网友太有才了,笑死我了。

上周,连载了有两年的<GUNDAM OO>在第二季的25集划下了句号。我个人的总体感觉一般般,当然,这其中包括它分成两季播放的给人一种不连贯感。但更多的,是认为它着眼于一个大局的概念,而没有刻画好细节。
中心的线索是GUNDAM系列一贯的,比较正统的"人类的进化",这次说的大义点,就是"相互理解,共同进步",这就是人类的"变革"。这部作品对于这一点还是表现得比较圆满,也交织着观点的冲突:
- 变革者统治人类与变革者引导人类。
- 有目的的战争与没有目的的战争。
- 和平的方式让人类相互理解与战争的方式让人类相互理解。
等等。
这部作品在画面,场景,音乐方面等都不失"高达水准",但在人物刻画上就比较差强人意了。
一开始就弄出了四个主角,还四个都是男的,这个场子铺大了。四人中,除了刹那与"伪娘",另外两个就有龙套的感觉,去掉这两人,对整个情节没有任何影响。但事实上,这两个人是有文章可以做的,可阿勒路亚的双重人格,洛克昂的亲兄弟间的关系这些都只是点到为止,都没有深入。其它"迷一样"的角色也太多了,刚出来的三小强,王留美及其它一些的所谓的观察者,还世代的宿命哦。还有那个沙兹的姐姐不是被什么人做掉了吗。很多东西都没有交代清楚。
另外,刹那最终也没有推倒玛莉娜,相信让很多人都失望了。
再说机体,这次数量有了,组合系,变形系,"酸浆果",MA,连RX-78都有。但对我而言确实没什么意外的惊喜,后面更变成OO-Raiser的单机秀了,反正它是无敌的,经典的"裸聊系统"也有。嗯,怎么说呢,不是这些机体设计的不好,没有出现在合适的位置的感觉。
算了算了,细细去剖析,我没那种宅情调。对于一部作品,更多是想它让我们记住了什么,这也是我认为最客观的标准,不过很可惜,这部作品似乎并没有让我记住什么场景,硬要说的话,就是最后一幕那个结婚的幸运儿吧。话又说回来,上一部的SEED我倒是有很多记忆:
- 拉克丝把Freedom交给基拉的那一幕。
- <从天而降的剑>那话,伴随着那首<Meteor>。
- 卡嘉丽的父亲自爆奥布,自由和正义在穿梭机上,<晓之车>奏响。
- 巴基露露叫大天使号发射阳电子破城炮的那一幕。
- 穆挡在大天使号前那一幕。
- ……
在OO连载间还看了两部TV动画,<叛逆的鲁鲁修>和<超时空要塞:边境>,这三部动画中个人评价最高的是MACROSS F。
2010年的OO剧场版……
话说,高达OO一完,就没什么看的了,有一种绝粮的感觉- -,4月要开始<钢之炼金术士>,我先去把第一部补了。